머신러닝을 공부하다 보면 가장 대표적인 3가지 학습 방법이 있다. 지도 학습, 비지도 학습, 강화 학습으로 나뉘며 아래 그림이 정말 쉽게 설명이 되어 있다.

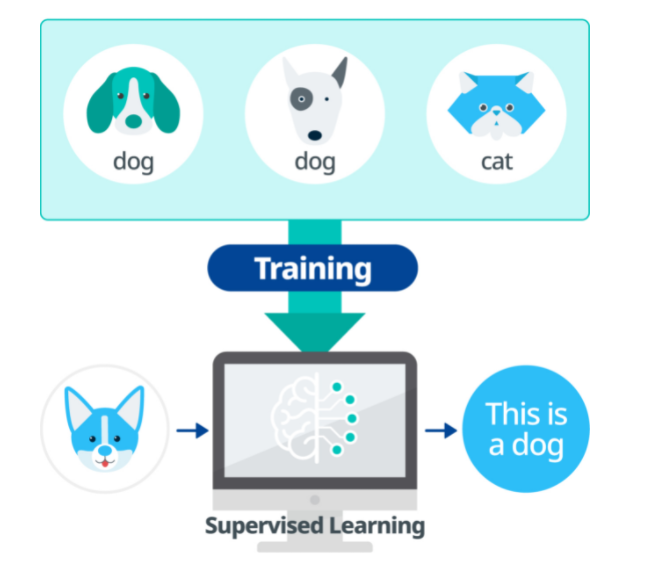
지도 학습(Superivised Learning)
지도 학습은 정답이 있는 데이터를 활용하여 데이터를 학습시킨다. 입력 값 X data가 주어지면 입력값에 대한 Label Y data를 주어 학습시키며 대표적으로 분류(Classification), 회귀(Regression) 문제가 있다.
# 정의
- 정답이 있는 라벨 데이터를 학습시켜 새로운 데이터에 대한 결과 예측하는 학습
# 유형
- 분류(Classfication)
- KNN
- MLP
- SVM
- DBN / CNN / RNN
2. 회귀(Regression)
- 다변량 회귀분석
- Logistic 회귀분석
- Poisson 회귀분석
비지도 학습(Unsupervised Learning)
비지도 학습은 정답(Label)이 없는 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과 값을 예측하는 방법이다. 대표적인 종류로는 군집화(Clustering)와 잠재 변수 모델이 있다.
# 정의
- 정답이 없는 라벨 데이터를 비슷한 특징끼리 군집화 하여 새로운 데이터에 대한 결과 예측하는 학습

# 유형
1. 군집화(Clustering)
- K-Means
- EM Clustering
- Dendrogram Clustering
2. 잠재 변수 모델
- PCA(Principal Component Analysis) / 주성분 분석
- LDA(Linear Discriminant Analysis) / 선형 판별 분석
- ICA(Independence Component Analysis) / 독립 성분 분석
강화 학습
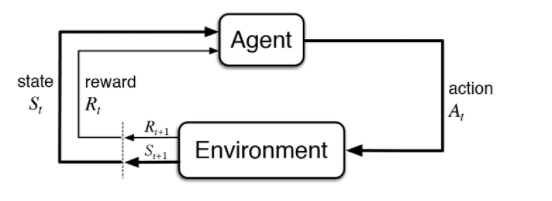
강화 학습은 상태 가치 함수와 행동 가치 함수를 기반으로 최대의 누적 보상을 획득하는 최적 정책 학습 알고리즘이다. 게임을 예로 들면 게임의 규칙을 따로 입력하지 않고 자신(Agent)이 게임 환경(Environment)에서 현재 상태(State)에서 높은 점수(Reward)를 얻는 방법을 찾아가며 행동(Action)하는 학습 방법으로 특정 학습 횟수를 초과하면 높은 점수(Reward)를 획득할 수 있는 전략이 형성된다. 대표적으로 강화 학습은 알파고를 예로 들 수 있다.
# 정의
- 상태 가치 함수와 행동 가치 함수를 기반으로, 최대의 누적 보상을 획득하는 최적 정책 학습 알고리즘
# 메커니즘
1. Agent : 학습 수행 주체
2. Environment : 보상 제공, 상태 변경
3. ACtion : 다음 취할 행동
4. Reward : 행동에 대한 보상
5. State : 상태 전이 확률
# 유형
1. Model-Free
- 사전 모델 없이 정책 학습
- Q-러닝, 시간차 적용
2. Model Based
- 상태 전이 확률 모델 기반 학습
- 몬테카를로 동적 프로그래밍
# 지도, 비지도, 강화 학습 비교
| 구분 | 지도 학습 | 비지도 학습 | 강화 학습 |
| 원리 | 레이블된 결과 함수 유추 학습 | 레이블 되지 않는 결과 학습 | 상태인지, 행동 보상 따른 학습 |
| 알고리즘 | SVM, Random Forest | Clustering, K-means | Q-러닝, DQN |
'CERTIFICATE' 카테고리의 다른 글
| NFT(Non-Fungible Token) (1) | 2021.05.10 |
|---|---|
| 메타버스(Meta Verse) (0) | 2021.05.08 |
| AD User 모든 사용자 마지막 로그인 파워쉘 쿼리 (0) | 2021.02.24 |
| 2020.10.15 지식의 정리가 필요한 날 (1) | 2020.10.15 |
| [Book Review] 2020.09.27 생각 정리의 기술1 (0) | 2020.09.27 |